앞선 포스팅에서 포워딩의 개념에 대해 간략하게 설명했다.
이번에는 조금 더 깊게 라우터가 어떻게 포워딩을 진행하는지 알아보자. 대략적인 라우터의 구조는 다음과 같다.
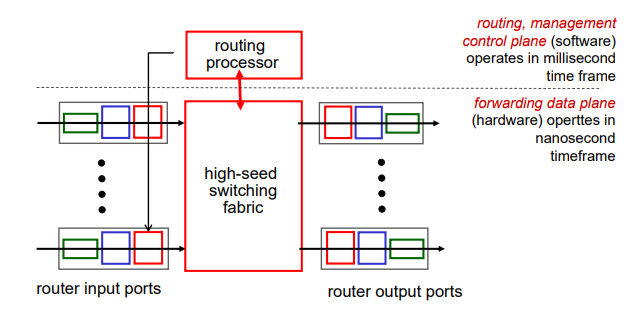
위 그림에서 위층은 제어 영역으로 라우팅 프로세서[Routing Processor]가 존재한다. 해당 프로세서는 특정 알고리즘을 통해 네트워크 상의 최적 경로를 설정한 후 이를 라우터[Switching fabric]에게 알려준다. 아래 계층은 포워딩이 일어나는 데이터 영역 계층이다. 라우터를 기준으로 왼쪽에는 입력 포트[Input ports]가 존재하고 오른쪽에는 출력 포트[Output ports]가 존재한다. 입력 포트와 출력 포트는 둘 다 물리 계층의 기능을 수행한다 (=즉, 단순히 Node와 Node끼리의 전송을 수행함)
입력 포트를 통해 들어온 데이터는 라우터 내에 있는 포워딩 테이블에 들어간다. 라우터는 포워딩 테이블을 보고 목적지는 어느 포트로 가야하는 지를 알아낸다. 그 후, 라우터는 해당 데이터를 목적지로 향할 수 있는 출력 포트로 내보낸다.
라우터는 포워딩 테이블을 기반으로 출력 포트로 해당 데이터를 내보낸다고 하였다. 그럼 포워딩 테이블을 기반으로 어떤식으로 처리해서 출력 포트를 정하는걸까?
스위치 방식은 두 가지가 있다. 하나는 'Destination-Based Forwarding'이라 하여 IP 주소를 기반으로 스위칭하는 방식이 있다. 또 다른 하나는 'Generalized Forwarding' 방식으로 헤더 내에 있는 특정 필드 값을 기반으로 스위칭하는 방식이다.
Destination-Based Forwarding 방식을 조금 더 자세히 이해해보자. 포워딩 테이블이 다음과 같다.

해당 방식에서는 Longest Prefix Matching 방식을 사용한다. 이름과 같이 '포워딩 테이블에서 가장 길게 대응되는 값이 무엇인지 찾고 거기서 지명한 링크로 데이터를 내보내는 방식'이다.
이 때 데이터가 '11001000 00010111 00010110 10100001'다. 이는 어떤 링크로 보내야할까? 포워딩 테이블에서 해당 데이터와 가장 길게 대응되는 것이 무엇인지 찾는다. '11001000 00010111 0001'까지는 모든 엔트리에 적합하다. 그 후의 데이터 값인 '0110'을 보자. 첫번째 엔트리는 '0***'지만 나머지 두 엔트리는 '1000', '1***'이다. 즉 '0100'과 가장 적합한 엔트리는 가장 첫 번째 엔트리이기 때문에 해당 데이터는 링크 0으로 출력될 것이다.
두 번째 데이터를 보자 '11001000 00010111 00011000 10101010'이다. 이 또한 모든 엔트리와 '11001000 00010111 0001'까지는 동일하다. 그 이후인 '1000'을 보았을 땐 어떤 엔트리에게 대응될까? 첫번째 엔트리는 '0****'이니까 맞지 않다. 두번째 엔트리는 '1000' 세번째 엔트리는 '1***'다. 두번째 엔트리도 맞고 세번째 엔트리도 맞는 것 같아보이지만, '가장 긴, 가장 일치하는 엔트리'에 출력되기 때문에 해당 데이터는 세번째보다 두번째와 더욱 적합하다고 볼 수 있다. 따라서 두 번째 엔트리인 링크 1로 출력될 것이다.
정리하자면, 입력 포트로 들어온 특정 데이터는 위와 같은 방식으로 자신이 내보내질 출력 포트가 결정되는 것이다.
이제 출력 포트를 결정하는 방식은 이해했다. 그러면 이번엔 다른 관점으로 포워딩을 바라봐보자. 만약에 100개의 입력 포트, 출력 포트를 가진 라우터가 있다고 해보자. 100개의 입력 포트로 100개의 데이터가 들어왔다. 그러나 만약 해당 데이터가 모두 하나의 출력 포트로 내보내져야한다면 어떤 일이 발생할까? 데이터가 슝~ 보내서 슝~가면 좋겠지만 짧은 시간에 굉장히 많은 데이터가 몰리면 지연이 발생할 수 밖에 없다. 따라서 이러한 관점으로 보았을 때 포워딩하는 방식과 구조는 여러 번 거쳐 발전되어 왔다. 아래를 보면서 어떻게 발전되어 왔는지 살펴보자.
스위칭은 세 가지 타입이 있다. 메모리를 거치는 구조, 버스형 구조, 크로스 바 구조다.

1. 메모리를 통한 스위칭
가장 직관적이고 단순한 방식이다. 초기 라우터에서 입/출력 포트를 결정할 땐 CPU의 개입이 필요했다. CPU가 직접 입/출력 포트를 지정하는 방식이다.

이와 같은 방식은 단점이 있다. 해당 데이터는 한 번에 하나의 메모리에 읽기/쓰기 작업을 수행하는 구조이기 때문에 읽기/쓰기 작업에 시간이 소모된다.
2. 버스를 통한 스위칭

프로세서의 개입없이 하나의 데이터는 입력 포트로 들어와서 출력 포트로 직접 나갈 수 있기에 위에서 생겼었던 문제는 해결할 수 있지만 여전히 한계는 존재한다. 만약 입력 포트로 여러 데이터가 한번에 들어오는 경우에, 버스에 싣을 수 있는 데이터는 오직 하나 뿐이다. 따라서 하나를 제외한 모든 데이터를 대기해야 한다.
3. 크로스바 형식의 스위칭

해당 스위칭 방식은 N개의 입력 포트를 N개의 출력 포트에 연결하는 2N 버스로 구성되어 있다. 각 수직 버스는 교차점에서 각 수평 버스와 교차하며 언제든지 열고 닫을 수 있다. 여러 데이터가 도착해도 병렬 처리가 가능하기에 지연이 단축된다. 그러나 만약 서로 다른 메시지가 같은 출력 포트로 보내지는 경우에는 하나의 데이터만 통과될 수 있기 때문에 목적 링크가 같은 또 다른 데이터는 대기해야 한다.
.
인풋 포트
아웃풋 포트 큐잉
패킷 스케줄링
'전공 > 네트워크' 카테고리의 다른 글
| 네트워크 계층 - IP에 대한 모든 것 #2. IPv4 & IPv6 (0) | 2020.10.27 |
|---|---|
| 네트워크 계층 - IP에 대한 모든 것 #1. IP의 주소 체계 (0) | 2020.10.27 |
| 네트워크 계층- 개요 (0) | 2020.10.27 |
| 데이터 링크 - ARP 동작 과정 (0) | 2020.10.18 |
| 데이터 링크- 대표 프로토콜(HDLC, 이더넷, X.25) (0) | 2020.10.18 |


